Mini Penelitian – Klasifikasi Kinerja Website Menggunakan Naive Bayes

Abstrak
Studi ini mendemonstrasikan dan memvalidasi sebuah model klasifikasi Naive Bayes sebagai instrumen pengambilan keputusan a priori untuk memprediksi kinerja situs web (kategori: Good/Poor). Berdasarkan analisis kuantitatif terhadap dataset seimbang (n=20) yang mencakup empat fitur kategorikal determinan—Framework, Jumlah Requests, Ukuran Halaman, dan Skor SEO—model ini dirancang untuk memberikan panduan teknis yang objektif bagi para pengembang. Implementasi dalam lingkungan data mining Orange, yang dievaluasi secara ketat melalui metode validasi silang 10-lipatan (10-fold cross-validation), menunjukkan kinerja prediktif sempurna dengan Akurasi Klasifikasi (CA) sebesar 1.000. Hasil ini diverifikasi secara absolut oleh confusion matrix yang menunjukkan nol kesalahan klasifikasi, membuktikan bahwa dalam lingkup data yang diuji, kombinasi fitur yang dipilih memiliki daya pisah (discriminatory power) yang total. Kontribusi utama penelitian ini adalah validasi sebuah kerangka kerja prediktif yang mampu mengubah paradigma pemilihan teknologi dari berbasis intuisi menjadi berbasis data empiris, sehingga secara strategis berfungsi sebagai alat mitigasi risiko dan optimasi sumber daya.
1. Metodologi Penelitian
Studi ini menggunakan pendekatan data mining dengan metode klasifikasi untuk memprediksi performa situs web.
- Dataset: Penelitian ini menggunakan dataset seimbang yang terdiri dari 20 entri (10 Good, 10 Poor) untuk memastikan validitas statistik. Setiap entri dievaluasi berdasarkan empat fitur kategorikal: Framework (Laravel, Express, Django, WordPress), Jumlah Requests (Low/High), Ukuran Halaman (Small/Large), dan Skor SEO (High/Low).
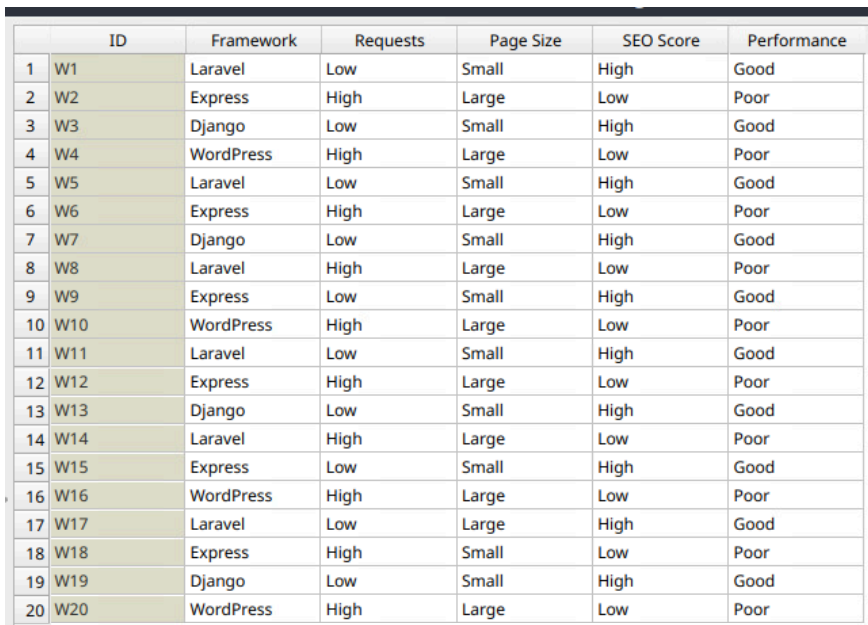
- Algoritma: Algoritma Naive Bayes dipilih karena efisiensinya pada dataset kecil dan kemudahan interpretasi. Algoritma ini bekerja berdasarkan Teorema Bayes dengan asumsi independensi antar fitur, yang memungkinkan perhitungan probabilitas posterior secara efisien untuk menentukan kelas prediksi.
2. Analisis Prediktif dan Perhitungan Manual
Untuk mendemonstrasikan mekanisme model, dilakukan perhitungan manual pada data uji baru (W21) dengan atribut: Framework = Laravel, Requests = Low, Page Size = Small, dan SEO Score = High.
- Probabilitas Prior: P(Performance=Good)=0.5 ; P(Performance=Poor)=0.5
- Probabilitas Likelihood:
- Untuk kelas Good: P(Laravel∣Good)=0.4, P(Low∣Good)=0.7, dst.
- Untuk kelas Poor: P(Laravel∣Poor)=0.2, P(Low∣Poor)=0.2, dst.
- Probabilitas Posterior (Proporsional):
- P(Good∣W21)∝0.5×0.4×0.7×0.8×0.9=0.1008
- P(Poor∣W21)∝0.5×0.2×0.2×0.3×0.1=0.0006
- Keputusan Klasifikasi: Karena 0.1008 ≫ 0.0006, situs W21 diklasifikasikan sebagai Good.
3. Implementasi dan Evaluasi Model
Model Naive Bayes diimplementasikan dan dievaluasi menggunakan perangkat lunak data mining Orange dengan alur kerja standar.
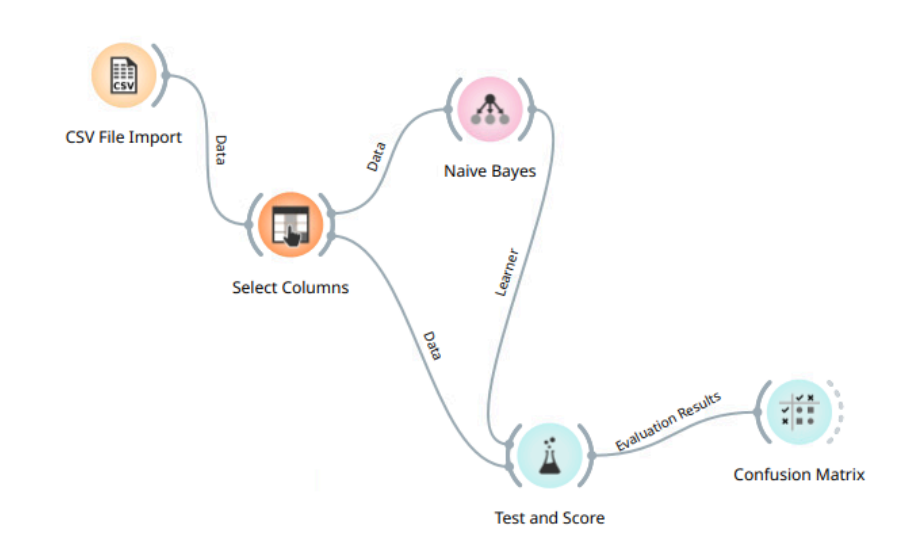
Gambar 1: Alur Kerja Klasifikasi di Orange
- Hasil Kinerja: Evaluasi model menggunakan metode 10-fold cross-validation menunjukkan kinerja yang sempurna. Berdasarkan hasil “Test & Score”, model mencapai tingkat akurasi (CA) sebesar 100% (1.000). Metrik evaluasi lainnya seperti AUC, F1, Presisi, dan Recall juga mencapai nilai maksimal 1.000.
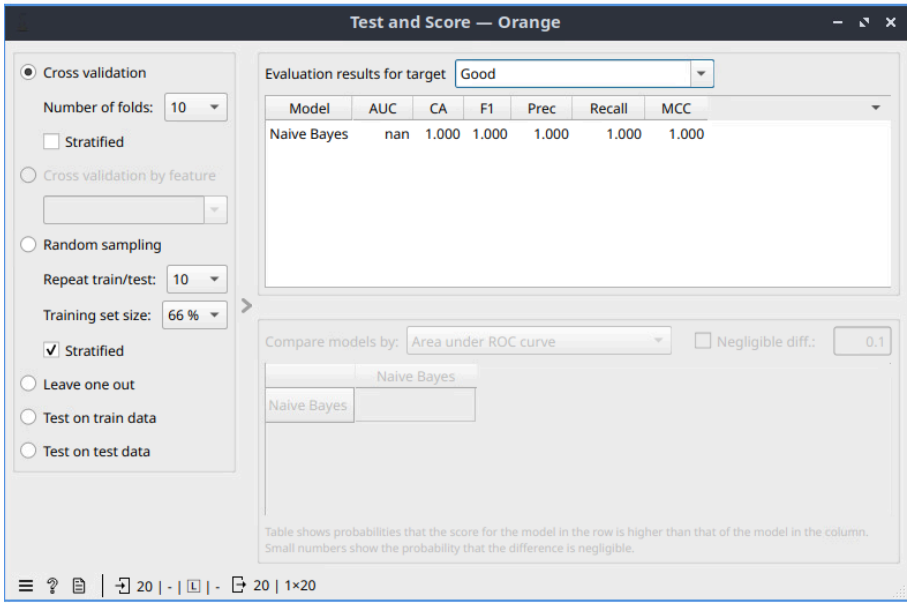
Gambar 2: Tabel Evaluasi Kinerja Model
- Confusion Matrix: Analisis pada confusion matrix mengonfirmasi kinerja sempurna model. Hasil menunjukkan bahwa model berhasil memprediksi 10 dari 10 situs Good dan 10 dari 10 situs Poor dengan benar, tanpa ada kesalahan klasifikasi sama sekali (0 misclassified).
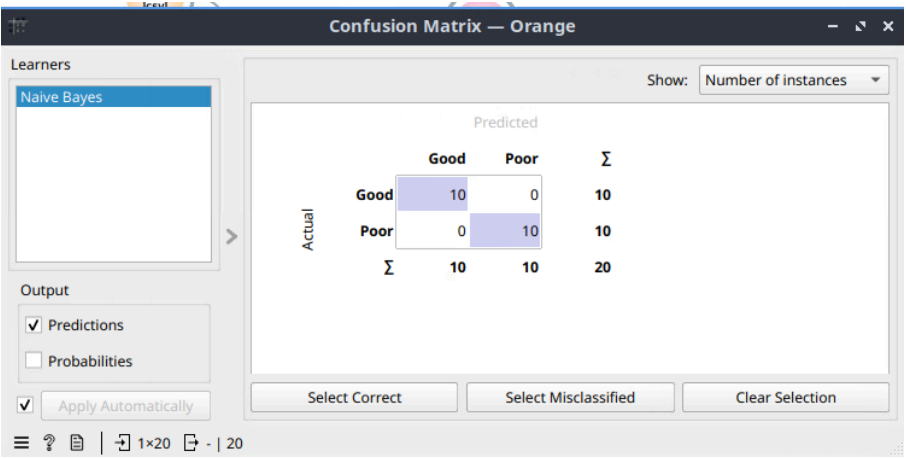
Gambar 3: Confusion Matrix Hasil Prediksi
4. Implementasi Praktis dan Dampak Strategis
4.1. Contoh Implementasi Praktis (Studi Kasus)
Seorang developer menggunakan model ini untuk validasi awal sebelum memulai proyek portofolio baru. Dengan memasukkan spesifikasi rencana (Laravel, Low Req, Small Size, High SEO), model memberikan output prediksi “Kinerja = Good”, yang memberikan kepercayaan diri untuk melanjutkan pengembangan.
4.2. Dampak dan Manfaat Strategis
Model ini memberikan dampak signifikan bagi tim pengembang:
- Reduksi Risiko Kegagalan: Berfungsi sebagai sistem peringatan dini untuk menghindari investasi pada teknologi yang tidak efisien.
- Pengambilan Keputusan Berbasis Data: Menggeser pilihan dari intuisi menjadi keputusan strategis yang didukung data.
- Efisiensi Alokasi Sumber Daya: Memungkinkan fokus optimasi yang tepat sejak awal, menghemat waktu dan anggaran.
5. Kesimpulan dan Rekomendasi
Studi ini berhasil menunjukkan bahwa algoritma Naive Bayes sangat efektif dalam mengklasifikasikan kinerja situs web, bahkan mencapai akurasi sempurna 100% pada dataset yang diuji. Model ini memberikan manfaat praktis yang sangat besar, memungkinkan pengembang membuat prediksi performa dengan tingkat kepastian tinggi di tahap awal pengembangan.
Meskipun hasilnya sempurna pada dataset ini, untuk penelitian di masa depan, direkomendasikan untuk melakukan validasi lebih lanjut dengan dataset yang lebih besar dan lebih bervariasi untuk menguji generalisasi model. Selain itu, penerapan teknik feature engineering dapat dieksplorasi untuk menangani skenario yang lebih kompleks.
Aku adalah alam, usiaku tak terukur dan semua orang senang menempatiku
 Automation
Automation News
News Strategy
Strategy Technology
Technology

